搜索到
2
篇与
的结果
-
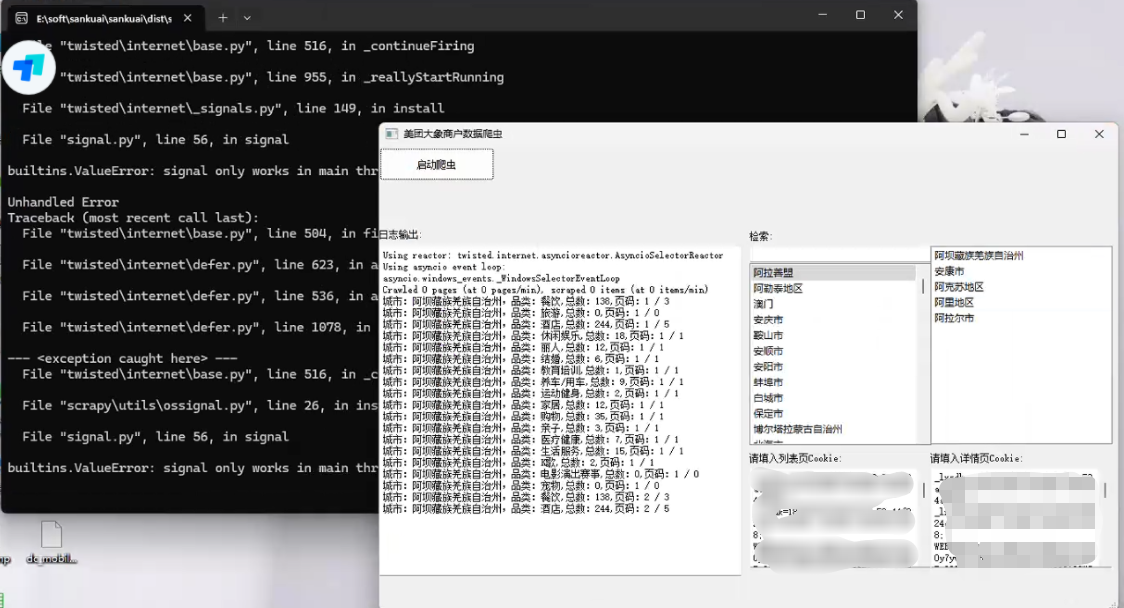
 美团旗下大象商户数据爬虫2-为爬虫绘制GUI并打包 前言公司最近的业务,继上文:https://lisok.cn/python/552.htmlcmd命令的使用有点麻烦,于是学习了一下PyQt5画了一个GUI实现有几个点需要提一下这里的日志输出是给logging添加了拦截器日志内容分成两部分如图,其中store记录的是自己代码中打印的,scrapy.utils.log是scrapy内部记录的一些日志统一添加一个handler处理 回调显示在界面上。store.pyfrom ui.mainwindow import signal class MyCustomHandler(logging.Handler): def __init__(self, signals): super(MyCustomHandler, self).__init__() self.signals = signals def emit(self, record): log_message = self.format(record) # 发送消息到 PyQt 界面 self.signals.log_signal.emit(log_message) class StoreSpider(scrapy.Spider): name = "store" allowed_domains = ["sale-pb.sankuai.com", 'crm.sankuai.com'] start_urls = ["https://sale-pb.sankuai.com/apigw/api/poi/ownership/poi-not-cooperated"] baseinfo_url = 'https://crm.sankuai.com/poi/sales/report/baseinfo?shopId={}' pageSize = 60 pageNum = 1 startCategoryId = 0 startRequest = True infoHeaders = {"Content-Type": "application/json; charset=UTF-8"} custom_settings = { 'LOG_LEVEL': 'INFO', 'LOG_FILE': 'sankuai-cus.log', } def __init__(self, *args, **kwargs): log_names = ['store', 'scrapy.utils.log', 'scrapy.extensions.logstats'] # 'scrapy.addons', 'scrapy.extensions.telnet', 'scrapy.middleware', # 'scrapy.crawler', 'scrapy.core.engine', for log_name in log_names: logging.getLogger(log_name).addHandler(MyCustomHandler(signal)) super().__init__(*args, **kwargs) # 设置Cookie self.cookies = kwargs.get('cookies', []) self.crawl_cities_ids = kwargs.get('crawl_cities_ids', []) # ....mainwindow.pyfrom PyQt5.QtCore import QThread, pyqtSignal, QObject from .ui_main_window.ui_mainwindow import Ui_MainWindow cities = [] class MySignal(QObject): log_signal = pyqtSignal(str) signal = MySignal() cookies = [] crawl_cities_ids = [] # ...其他的代码都很常规,打个包记录一下{cloud title="美团-大象商户爬虫.zip" type="bd" url="/我的分享/美团-大象商户爬虫.zip" password=""/}引用1.python scrapy框架 日志文件:https://blog.csdn.net/weixin_45459224/article/details/1001425372.[Python自学] PyQT5-子线程更新UI数据、信号槽自动绑定、lambda传参、partial传参、覆盖槽函数:https://www.cnblogs.com/leokale-zz/p/13131953.html3.[ PyQt入门教程 ] PyQt5中多线程模块QThread使用方法:https://www.cnblogs.com/linyfeng/p/12239856.html4.Scrapy Logging:https://docs.scrapy.org/en/latest/topics/logging.html#logging-configuration5.在线程中启动scrapy以及多次启动scrapy报错的解决方案(ERROR:root:signal only works in main thread):https://blog.csdn.net/Pual_wang/article/details/106466017
美团旗下大象商户数据爬虫2-为爬虫绘制GUI并打包 前言公司最近的业务,继上文:https://lisok.cn/python/552.htmlcmd命令的使用有点麻烦,于是学习了一下PyQt5画了一个GUI实现有几个点需要提一下这里的日志输出是给logging添加了拦截器日志内容分成两部分如图,其中store记录的是自己代码中打印的,scrapy.utils.log是scrapy内部记录的一些日志统一添加一个handler处理 回调显示在界面上。store.pyfrom ui.mainwindow import signal class MyCustomHandler(logging.Handler): def __init__(self, signals): super(MyCustomHandler, self).__init__() self.signals = signals def emit(self, record): log_message = self.format(record) # 发送消息到 PyQt 界面 self.signals.log_signal.emit(log_message) class StoreSpider(scrapy.Spider): name = "store" allowed_domains = ["sale-pb.sankuai.com", 'crm.sankuai.com'] start_urls = ["https://sale-pb.sankuai.com/apigw/api/poi/ownership/poi-not-cooperated"] baseinfo_url = 'https://crm.sankuai.com/poi/sales/report/baseinfo?shopId={}' pageSize = 60 pageNum = 1 startCategoryId = 0 startRequest = True infoHeaders = {"Content-Type": "application/json; charset=UTF-8"} custom_settings = { 'LOG_LEVEL': 'INFO', 'LOG_FILE': 'sankuai-cus.log', } def __init__(self, *args, **kwargs): log_names = ['store', 'scrapy.utils.log', 'scrapy.extensions.logstats'] # 'scrapy.addons', 'scrapy.extensions.telnet', 'scrapy.middleware', # 'scrapy.crawler', 'scrapy.core.engine', for log_name in log_names: logging.getLogger(log_name).addHandler(MyCustomHandler(signal)) super().__init__(*args, **kwargs) # 设置Cookie self.cookies = kwargs.get('cookies', []) self.crawl_cities_ids = kwargs.get('crawl_cities_ids', []) # ....mainwindow.pyfrom PyQt5.QtCore import QThread, pyqtSignal, QObject from .ui_main_window.ui_mainwindow import Ui_MainWindow cities = [] class MySignal(QObject): log_signal = pyqtSignal(str) signal = MySignal() cookies = [] crawl_cities_ids = [] # ...其他的代码都很常规,打个包记录一下{cloud title="美团-大象商户爬虫.zip" type="bd" url="/我的分享/美团-大象商户爬虫.zip" password=""/}引用1.python scrapy框架 日志文件:https://blog.csdn.net/weixin_45459224/article/details/1001425372.[Python自学] PyQT5-子线程更新UI数据、信号槽自动绑定、lambda传参、partial传参、覆盖槽函数:https://www.cnblogs.com/leokale-zz/p/13131953.html3.[ PyQt入门教程 ] PyQt5中多线程模块QThread使用方法:https://www.cnblogs.com/linyfeng/p/12239856.html4.Scrapy Logging:https://docs.scrapy.org/en/latest/topics/logging.html#logging-configuration5.在线程中启动scrapy以及多次启动scrapy报错的解决方案(ERROR:root:signal only works in main thread):https://blog.csdn.net/Pual_wang/article/details/106466017 -
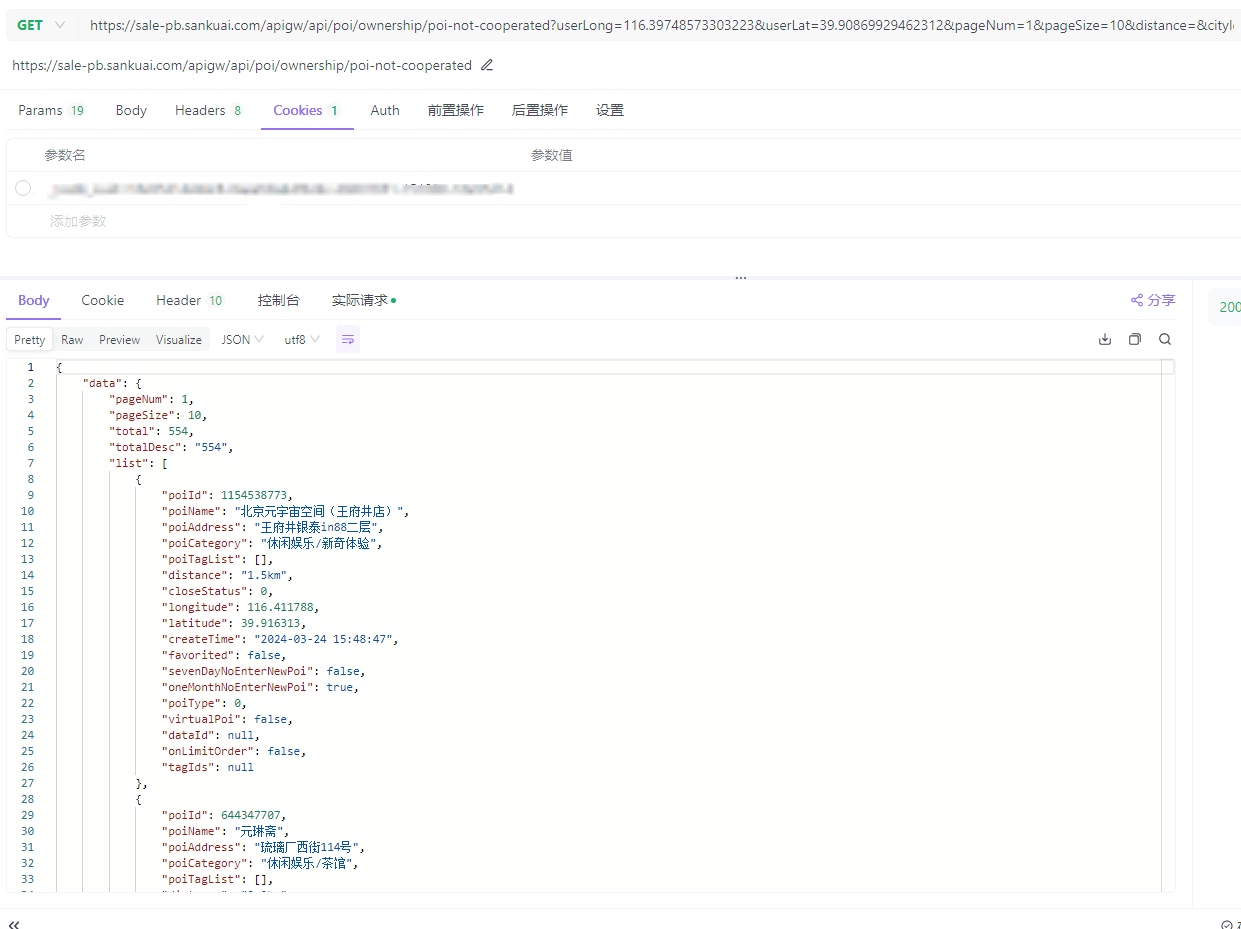
美团旗下大象商户数据爬虫1-Python将Scrapy程序打包成exe 本文开发环境:Python3.9前言最近公司有业务开展到爬美团下 大象的商户信息# 主要是这两个域名 allowed_domains = ["sale-pb.sankuai.com", 'crm.sankuai.com']Pycharm在开发机器上采集占用太高了,于是想打包成exe部署到服务器上跑环境配置包配置:包名版本Scrapy2.11.1pyinstaller6.5.0 步骤一、编写程序入口参考官方文档:https://doc.scrapy.org/en/latest/topics/practices.htmlsankuai/run.pyfrom scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings # 下面的包是项目中用到的包,根据自己的项目自行添加,也可以根据打包运行的报错信息,逐个添加 import js2xml import os settings = get_project_settings() process = CrawlerProcess(settings) process.crawl('store') # 填入你需要运行的文件名 process.start()二、数据保存本来是想用FEED来保存数据,可以通过控制台来控制保存地址sankuai/run.pysettings = get_project_settings() settings.setdict({ 'FEED_FORMAT': 'csv', 'FEED_URI': os.path.join(os.path.dirname(os.path.abspath(__file__)), 'data.csv') }, priority="project") process = CrawlerProcess(settings)但是测试发现只会创建文件,并不会写入数据,这里没有解决 有后续了再贴替代方案使用pipeline.pysankuai/sankuai/pipeline.pyclass SankuaiPipeline: def __init__(self): # data文件夹不存在则创建 if not os.path.exists('./data'): os.mkdir('./data') def process_item(self, item, spider): with open('./data/' + item.get('cityName') + '.csv', 'a+', encoding='gbk', newline='') as f: writer = csv.writer(f) writer.writerow((item.get('cityName'), item.get('phone'), item.get('phone2'))) return item sankuai/sankuai/settings.py# ... # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { "sankuai.pipelines.SankuaiPipeline": 300, } # ...三、打包打包执行命令:pyinstaller.exe .\run.py打包后的文件会位于sankuai/dist/run/run.exe,通过cmd运行项目中读取的文件需要放到同一个运行目录中,我这里是category.json和city.json还有两个Cookie文件四、运行出现KeyError: 'Spider not found:爬虫名,可以将项目源码和打包程序放在一块,即打包时生成时的目录结构,不要改变,拷贝时连同项目整体拷贝,亲测有效。打包时直接将sankuai目录压缩了,不然会出现其他问题,当然安全性没有保障(源码都泄露出去了)公司自用就无所谓了引用1.python 将Scrapy项目打包成exe及注意事项 :https://www.cnblogs.com/zhengxianfa/p/16767965.html2.【scrapy打包】使用pyinstaller将scrapy项目打包成独立可执行exe,及可能遇到的问题和解决方法:https://blog.csdn.net/qq_51543898/article/details/1368468103.The application can not locate Python39.dll (126)找不到指定的模块。解决方法:https://blog.csdn.net/wushaoqiu2011/article/details/1101824974.用Pyinstaller打包Scrapy项目问题解决!!!:https://pyqt5.blog.csdn.net/article/details/79017358