搜索到
1
篇与
的结果
-
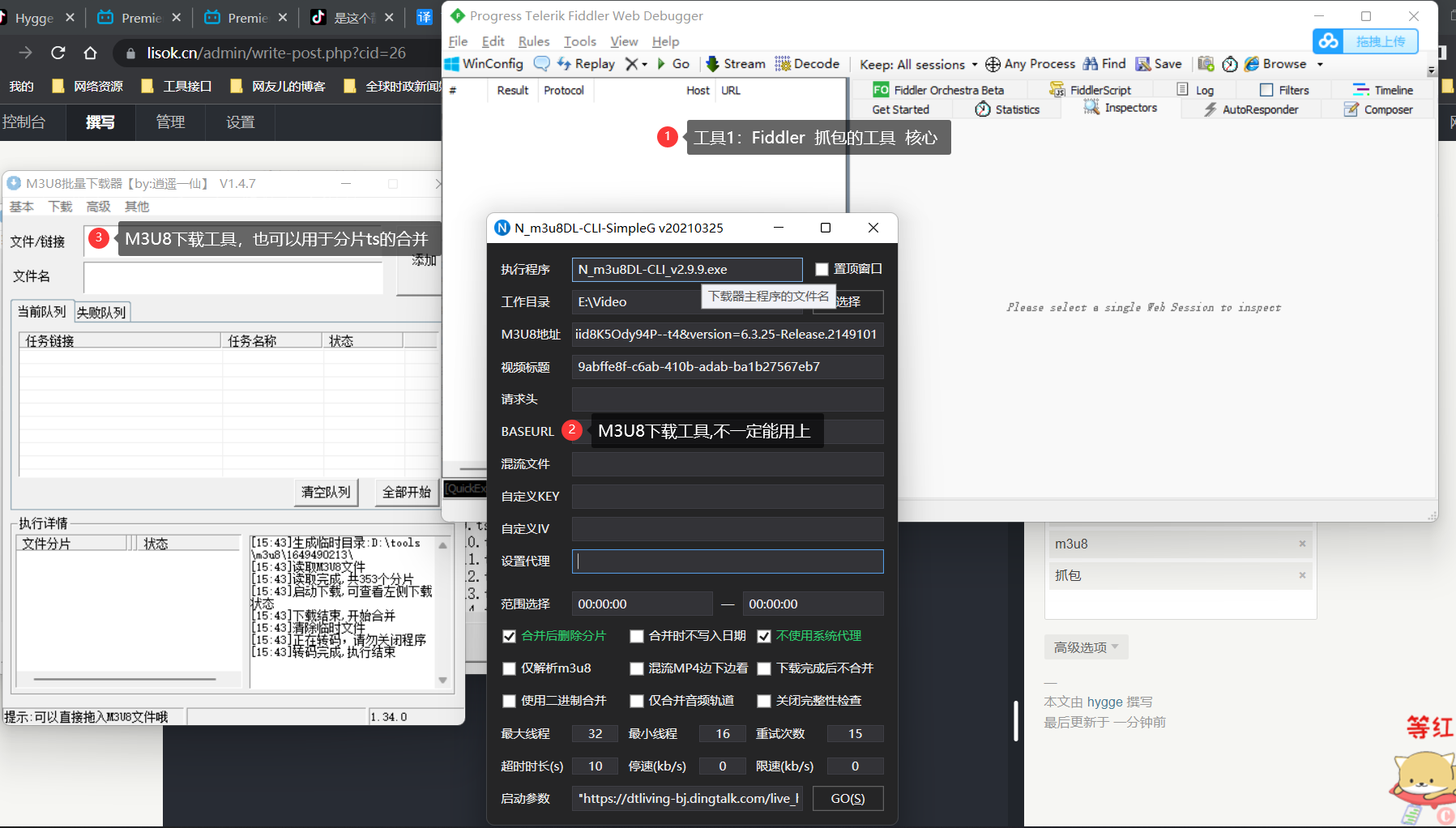
 钉钉视频回放下载 1.环境准备除了Fiddler需要稍微配置下,其他的都是拿来即用的。下载地址: https://wwu.lanzouw.com/b011h8yuh 密码:9csk2.Fiddler的配置设置Fiddler捕捉HTTPS流量点击Tools,选择Options... 这儿个端口记下来,待会需要用到,默认的是88883.启动DingTalk ::(哈哈) 为了节省空间 用的别人的图,但是这里的端口要和刚才强调的一致奥,我刚才的是8888,所以这里也要填8888若测试连接失败可以检查如下item:测试是否有其他软件接管了你的浏览器代理(Clash)访问http://127.0.0.1:port/ 下载并安装证书重新打开钉钉和Fiddler4.Fiddler配置注入1.选中 Fiddler Script。 2.选择 OnBeforeResponse,会自动定位。 3.将如下代码粘贴到图中位置var sToInsert = "<script src='https://cdn.jsdelivr.net/gh/Tencent/[email protected]/dist/vconsole.min.js'></script><script>var vConsole = new VConsole();</script>" oSession.utilDecodeResponse(); oSession.utilReplaceOnceInResponse('</head>', sToInsert + '</head>', 0); 5.监测流量打开钉钉回放页面,发现右下角多了 vConsole,一个绿色的按钮。点击这个按钮,填入以下代码: vConsole.showTab("network"); 6.M3U8下载丢到 M3U8 下载器(分享的两个都可以使用)里下载: 等待下载完成即可,下载后的视频在 M3U8 下载器设置的文件夹内。若你的视频在此刻可以下载,那么恭喜您已经完成了本文的阅读,若提示如下内容 请接着往下看~7.手动分片下载这种情形需要自己来下载所有的分片流程:获取到m3u8的文件内容 -> 将每一个ts链接拼接上前缀 -> 用脚本批量下载并合并获取m3u8的响应体(响应体可以在fd中直接获取到,也可以在上步配置的流量拦截中获取)将上一步的响应体存到文件中,并记录下抓包抓到的ts文件前缀 需要使用脚本拼接成 地址前缀 + 分片地址的形式,为之后的下载做准备。# -*- coding: utf-8 -*- import requests # 读取target.m3u8文件 def read_m3u8(file_name): with open(file_name, 'r') as f: lines = f.readlines() return lines origin_group = read_m3u8('target.m3u8') # 循环origin_group,提取出ts文件名 ts_list = [] for line in origin_group: if line.startswith('#'): continue else: # 拼接每一个ts的前缀 ts_list.append('https://dtliving-bj.dingtalk.com/live_hp/' + line.strip()) # 循环ts_list,下载ts文件 for ts in ts_list: r = requests.get(ts) with open('Download' + ts[ts.rfind('/'):ts.find('?')], 'wb') as f: print('Downloading: ' + ts[ts.rfind('/') + 1:ts.find('?')]) f.write(r.content) print('下载完成') 将如上代码进行修改 适配你的情况至此就完成了钉钉录播视频的下载+合并 ::(勉强)7.附注本文参考:通过抓包下载钉钉直播回放:https://www.52pojie.cn/thread-1613216-1-1.html
钉钉视频回放下载 1.环境准备除了Fiddler需要稍微配置下,其他的都是拿来即用的。下载地址: https://wwu.lanzouw.com/b011h8yuh 密码:9csk2.Fiddler的配置设置Fiddler捕捉HTTPS流量点击Tools,选择Options... 这儿个端口记下来,待会需要用到,默认的是88883.启动DingTalk ::(哈哈) 为了节省空间 用的别人的图,但是这里的端口要和刚才强调的一致奥,我刚才的是8888,所以这里也要填8888若测试连接失败可以检查如下item:测试是否有其他软件接管了你的浏览器代理(Clash)访问http://127.0.0.1:port/ 下载并安装证书重新打开钉钉和Fiddler4.Fiddler配置注入1.选中 Fiddler Script。 2.选择 OnBeforeResponse,会自动定位。 3.将如下代码粘贴到图中位置var sToInsert = "<script src='https://cdn.jsdelivr.net/gh/Tencent/[email protected]/dist/vconsole.min.js'></script><script>var vConsole = new VConsole();</script>" oSession.utilDecodeResponse(); oSession.utilReplaceOnceInResponse('</head>', sToInsert + '</head>', 0); 5.监测流量打开钉钉回放页面,发现右下角多了 vConsole,一个绿色的按钮。点击这个按钮,填入以下代码: vConsole.showTab("network"); 6.M3U8下载丢到 M3U8 下载器(分享的两个都可以使用)里下载: 等待下载完成即可,下载后的视频在 M3U8 下载器设置的文件夹内。若你的视频在此刻可以下载,那么恭喜您已经完成了本文的阅读,若提示如下内容 请接着往下看~7.手动分片下载这种情形需要自己来下载所有的分片流程:获取到m3u8的文件内容 -> 将每一个ts链接拼接上前缀 -> 用脚本批量下载并合并获取m3u8的响应体(响应体可以在fd中直接获取到,也可以在上步配置的流量拦截中获取)将上一步的响应体存到文件中,并记录下抓包抓到的ts文件前缀 需要使用脚本拼接成 地址前缀 + 分片地址的形式,为之后的下载做准备。# -*- coding: utf-8 -*- import requests # 读取target.m3u8文件 def read_m3u8(file_name): with open(file_name, 'r') as f: lines = f.readlines() return lines origin_group = read_m3u8('target.m3u8') # 循环origin_group,提取出ts文件名 ts_list = [] for line in origin_group: if line.startswith('#'): continue else: # 拼接每一个ts的前缀 ts_list.append('https://dtliving-bj.dingtalk.com/live_hp/' + line.strip()) # 循环ts_list,下载ts文件 for ts in ts_list: r = requests.get(ts) with open('Download' + ts[ts.rfind('/'):ts.find('?')], 'wb') as f: print('Downloading: ' + ts[ts.rfind('/') + 1:ts.find('?')]) f.write(r.content) print('下载完成') 将如上代码进行修改 适配你的情况至此就完成了钉钉录播视频的下载+合并 ::(勉强)7.附注本文参考:通过抓包下载钉钉直播回放:https://www.52pojie.cn/thread-1613216-1-1.html