



CCPC训练赛回顾
时间:2023-04-25 6:30 ~ 8:30
之前写算法一直用的Java,最近抽风= =,想从零开始学C++。
比赛的时候前半段用的就是C++
说下感受:
- 借的电脑比赛的,只有裸机笔记本..没键鼠太麻烦了。
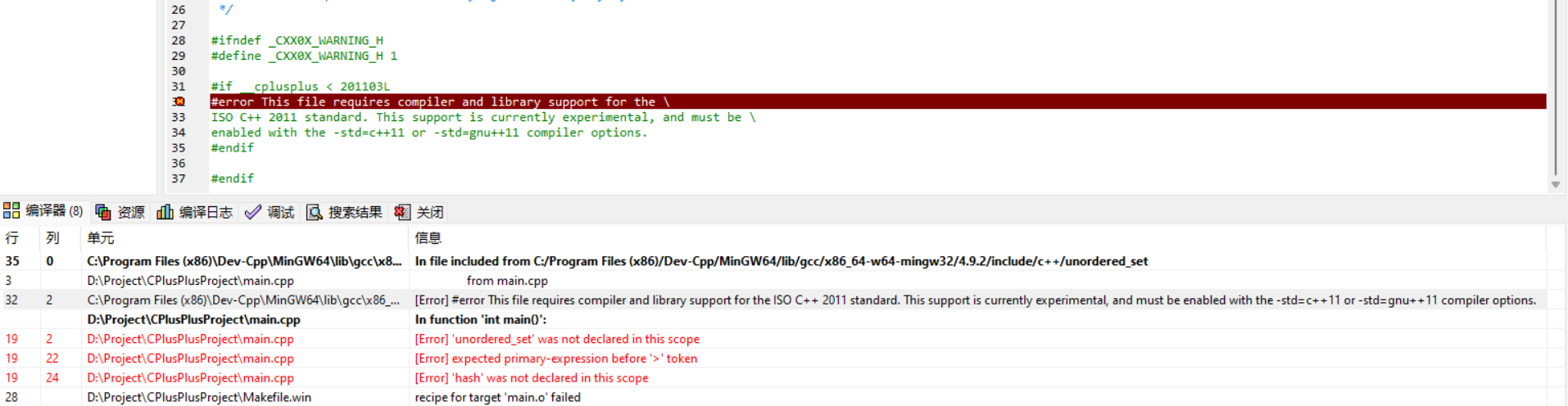
C++还是不熟悉,题都过了一遍,不知道什么情况就是不能Ac,又换成Java过(一直没用,还好没忘!- 现在回顾才发现比赛的时候真是太愚蠢了!
我感觉对我来说是三道简单题三道难题,关键是简单题耗时太长了,没空研究难题了呜呜呜。

A. 不晔的幸运数字
题目描述
不晔认为1和6是幸运的数字,当一个正整数只包含1和6的时候,这个数就是幸运的。(如166、666都是幸运的数,而36、216不是)现在告诉你一个正整数a,请告诉不晔距离这个数字最近的幸运数字。
输入描述
输入共一行一个正整数a
输出描述
输出距离a最近的幸运数字(如果有两个幸运数字和a距离最近且相同,输出小的那一个)
样例输入
8样例输出
6我的解答
C++
#include <iostream>
#include <string>
using namespace std;
bool isLuckNum(int n) {
for (char chr: to_string(n))
if (chr != '1' && chr != '6')
return false;
return true;
}
int main() {
int a, aCopy;
cin >> a;
aCopy = a;
int answer;
while (1) {
if (isLuckNum(aCopy)) {
answer = aCopy;
break;
}
aCopy++;
}
aCopy = a;
while (1) {
if (isLuckNum(aCopy)) {
if (answer - a > aCopy - answer || answer - a == aCopy - answer) answer = aCopy;
break;
}
aCopy--;
}
cout << answer << endl;
return 0;
}B.复杂去重
题目描述
现在有有1个长度为n的数组,求该数组中有几种数字。
输入描述
输入共两行。第一行一个正整数n,表示数组大小;第二行n个数为数组中元素。(1≤n≤1e3,1≤ai≤1e9)
输出描述
该数组中有几种数字(即数组去重后的大小)
样例输入
5
2 1 3 1 4样例输出
4提示
这题是乱序数据,但是n没有那么大了(暴力吧,少年)
我的解答
C++
#include <iostream>
#include <set>
using namespace std;
int main() {
int n, temp;
cin >> n;
set<int> set1;
for (int i = 0; i < n; i++) {
cin >> temp;
set1.insert(temp);
}
cout << set1.size() << endl;
return 0;
}Java
import java.util.HashSet;
import java.util.Set;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
Set set = new HashSet<Integer>();
for (int i = 0; i < n; i++) {
int t = scanner.nextInt();
set.add(t);
}
System.out.println(set.size());
}
}C.汉诺塔
题目描述
古老的汉诺塔问题是:用最少的步数将N个半径互不相等的圆盘从1号柱利用2号柱全部移动到3号柱,在移动过程中小盘永远在大盘上边。 现在再加上一个条件:不允许从1号柱直接把盘移动到3号柱, 也不允许从3号柱直接移动到1号柱。把盘按半径从小到大1——N进行编号。每种状态用N个整数表示, 第i个整数表示第i号盘所在的柱的编号。则N=2时的移动方案为(1,1)》(2,1)》(3,1)》(3,2)》(2,2)》(1,2)》(1,3)》(2,3) 》(3,3)初始状态为0步,变成求在某步数时的状态。
输入描述
输入文件的第一行为整数T(1<=T<=100),表示输入数据的组数。接下来的T行,每行有两个整数N,M(1<=N<=19, 0<=M<=移动N个圆盘需要的次数)
输出描述
输入文件一共T行对于每组输入数据,输出N个整数表示移动N个盘在M步时的状态,每两个数之间用一个空格隔开,行首和行末不要有多余的空格。
样例输入
3
2 0
2 1
2 2样例输出
1 1
2 1
3 1D.数的反转
题目描述
输入一个整数,你所需要做的是将其反转,输出的仍然是一个整数
输入描述
第一行N表示将会有几个测试数据(N<=100);接下来的N行每行一个整数(每行得整数不超过100000000000)。
输出描述
输出反转之后的整数,每行一个。
样例输入
1
127样例输出
721我的解答
C++
#include <iostream>
#include <algorithm>
#include <string>
using namespace std;
int main() {
int n;
string str;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> str;
reverse(str.begin(), str.end());
int res = stoi(str);
cout << res << endl;
}
return 0;
}Java
import java.util.Scanner;
public class Main {
static int reverseStr(String str) {
StringBuilder sb = new StringBuilder();
for (int i = str.length() - 1; i >= 0; i--) {
sb.append(str.charAt(i));
}
return Integer.parseInt(sb.toString());
}
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in);
int n = scanner.nextInt();
for (int i = 0; i < n; i++) {
int t = scanner.nextInt();
System.out.println(reverseStr(t + ""));
}
}
}E.拼音字母
题目描述
在很多软件中,输入拼音的首写字母就可以快速定位到某个词条。比如,在铁路售票软件中,输入: “bj”就可以定位到“北京”。怎样在自己的软件中实现这个功能呢?问题的关键在于:对每个汉字必须能计算出它的拼音首字母。
GB2312汉字编码方式中,一级汉字的3755个是按照拼音顺序排列的。我们可以利用这个特征,对常用汉字求拼音首字母。
GB2312编码方案对每个汉字采用两个字节表示。第一个字节为区号,第二个字节为区中的偏移号。为了能与已有的ASCII编码兼容(中西文混排),区号和偏移编号都从0xA1开始。
我们只要找到拼音a,b,c,...x,y,z 每个字母所对应的GB2312编码的第一个汉字,就可以定位所有一级汉字的拼音首字母了(不考虑多音字的情况)。下面这个表给出了前述信息。请你利用该表编写程序,求出常用汉字的拼音首字母。
a 啊 B0A1
b 芭 B0C5
c 擦 B2C1
d 搭 B4EE
e 蛾 B6EA
f 发 B7A2
g 噶 B8C1
h 哈 B9FE
j 击 BBF7
k 喀 BFA6
l 垃 C0AC
m 妈 C2E8
n 拿 C4C3
o 哦 C5B6
p 啪 C5BE
q 期 C6DA
r 然 C8BB
s 撒 C8F6
t 塌 CBFA
w 挖 CDDA
x 昔 CEF4
y 压 D1B9
z 匝 D4D1
输入描述
用户先输入一个整数n (n<100),表示接下来将有n行文本。接着输入n行中文串(每个串不超过50个汉字)。
输出描述
程序则输出n行,每行内容为用户输入的对应行的汉字的拼音首字母。
字母间不留空格,全部使用大写字母。
样例输入
3
大家爱科学
北京天安门广场
软件大赛样例输出
DJAKX
BJTAMGC
RJDSF.表格计算
题目描述
某次无聊中, atm 发现了一个很老的程序。这个程序的功能类似于 Excel ,它对一个表格进行操作。
不妨设表格有 n 行,每行有 m 个格子。
每个格子的内容可以是一个正整数,也可以是一个公式。
公式包括三种:
- SUM(x1,y1:x2,y2) 表示求左上角是第 x1 行第 y1 个格子,右下角是第 x2 行第 y2 个格子这个矩形内所有格子的值的和。
- AVG(x1,y1:x2,y2) 表示求左上角是第 x1 行第 y1 个格子,右下角是第 x2 行第 y2 个格子这个矩形内所有格子的值的平均数。
- STD(x1,y1:x2,y2) 表示求左上角是第 x1 行第 y1 个格子,右下角是第 x2 行第 y2 个格子这个矩形内所有格子的值的标准差。
标准差即为方差的平方根。
方差就是:每个数据与平均值的差的平方的平均值,用来衡量单个数据离开平均数的程度。
公式都不会出现嵌套。
如果这个格子内是一个数,则这个格子的值等于这个数,否则这个格子的值等于格子公式求值结果。
输入这个表格后,程序会输出每个格子的值。atm 觉得这个程序很好玩,他也想实现一下这个程序。
输入描述
第一行两个数 n, m 。
接下来 n 行输入一个表格。每行 m 个由空格隔开的字符串,分别表示对应格子的内容。
输入保证不会出现循环依赖的情况,即不会出现两个格子 a 和 b 使得 a 的值依赖 b 的值且 b 的值依赖 a 的值。
输出描述
输出一个表格,共 n 行,每行 m 个保留两位小数的实数。
数据保证不会有格子的值超过 1e6 。
样例输入
3 2
1 SUM(2,1:3,1)
2 AVG(1,1:1,2)
SUM(1,1:2,1) STD(1,1:2,2)样例输出
1.00 5.00
2.00 3.00
3.00 1.48提示
对于 30% 的数据,满足: n, m <= 5
对于 100% 的数据,满足: n, m <= 50
经验
1.抓紧过一边C++的数据STL库
2.对各种变量类型的范围要把控,知道什么题什么范围用什么变量最合适
3.多刷题!




评论 (0)