搜索到
7
篇与
的结果
-

-
蚂蚁智学题库爬虫并整理到Excel 接的小私活,目标爬取下来题库并整理到Excel里。目标站点:https://www.mayizhixue.cn/{cloud title="蚂蚁智学" type="bd" url="https://pan.baidu.com/s/1pjg1vTojaazfebpCT1J9SQ?pwd=d2nv" password="d2nv"/}import requests from openpyxl import Workbook from openpyxl.utils import get_column_letter from openpyxl import load_workbook import os common_headers = { 'Authorization': 'TOKEN', } record_id = 1 wb = load_workbook(filename='sample.xlsx') ws = wb.active rows = ws.rows def get_target_row_number(): rows = ws.rows idx = 1 for row in rows: # for cell in row: # print(cell.value, end=' ') # print() if row[0].value is None: return idx idx = idx + 1 return idx def write_row(row, kIndex=None): global record_id rowNumber = get_target_row_number() # print(f"当前行数:{rowNumber}") if kIndex is None: ws.cell(row=rowNumber, column=1).value = record_id else: ws.cell(row=rowNumber, column=1).value = str(record_id) + '.' + str(kIndex) ws.cell(row=rowNumber, column=2).value = row.get('title', '') ws.cell(row=rowNumber, column=3).value = row.get('type', '') # ws.cell(row=rowNumber, column=4).value = row.get('type') # 分数 # ws.cell(row=rowNumber, column=5).value = row.get('type') # 难度 option_idx = 0 for option in row.get('options', []): if 6 + option_idx >= 11: break ws.cell(row=rowNumber, column=6 + option_idx).value = option option_idx = option_idx + 1 ws.cell(row=rowNumber, column=11).value = row.get('answer', '') ws.cell(row=rowNumber, column=12).value = row.get('analysis', '') if kIndex is None: record_id = record_id + 1 def map_type_kv(key): # 1-单选题 2-多选题 6-共享题干题 type = '单选题' if key in ('1', 1): type = '单选题' elif key in ('2', 2): type = '多选题' elif key in ('3', 3): type = '不定项选择题' elif key in ('4', 4): type = '判断题' elif key in ('6', 6): type = '材料题' else: print('不支持的类型:%s' % key) exit() return type def get_test_question(sectionId): params = { 'sectionId': sectionId, 'type': '2', } response = requests.get('https://wx.yiwenjy.cn/yunlian_pc/querySubjectList', params=params, headers=common_headers).json() data = response.get('data') handle_data_2_excel(data) def handle_data_2_excel(data): for i in data: # 此时 i 为对象,取出所有key并遍历 for key in i.keys(): type = map_type_kv(key) # 开始遍历这一题型的所有题目 if type in ['单选题', '多选题', '不定项选择题', '判断题']: for j in i.get(key): row = { 'title': j.get('issue'), 'type': type, 'options': [], 'answer': j.get('answer'), 'analysis': j.get('analysis') } options = j.get('sOption') # 使用|分割选项 options = options.split('|') for k in options: # j为A.选项内容 所以取第三个字符开始 row['options'].append(k[2:]) write_row(row) elif type == '材料题': for j in i.get(key): row = { 'title': j.get('stem'), 'type': type } write_row(row) # 开始爬下面的point kIndex = 1 for k in j.get('childre', []): subtype = map_type_kv(k.get('subType')) row = { 'title': k.get('issue'), 'type': subtype, 'options': [], 'answer': k.get('answer'), 'analysis': k.get('analysis') } options = k.get('sOption') # 使用|分割选项 options = options.split('|') for opt in options: # j为A.选项内容 所以取第三个字符开始 row['options'].append(opt[2:]) write_row(row, kIndex) kIndex = kIndex + 1 def get_exam_question(paperId): response = requests.get( 'https://wx.yiwenjy.cn/yunlian_pc/queryoPaperSubjectList', params={ 'paperId': paperId, 'mode': '2' }, headers=common_headers).json() data = response.get('data') handle_data_2_excel(data) def get_catalogue(courseName, courseId): response = requests.get('https://wx.yiwenjy.cn/yunlian_pc/querySectionList', params={ 'courseId': courseId }, headers=common_headers).json() data = response.get('data') for i in data: print(f"当前章节ID:{i.get('id')},章节名称:{i.get('sectionName')}") # 创建相关文件夹 if not os.path.exists(courseName + '/' + i.get('sectionName')): os.makedirs(courseName + '/' + i.get('sectionName')) # 这里需要一直向下判断是否有子节点 copy_i = i # dfs算法 access_next_level(courseName + "/", copy_i) def access_next_level(path, item): global wb, ws, rows, record_id # dfs算法 开始不断找下级 向上返回 if item.get('children') is not None: path = path + item.get('sectionName') + '/' for i in item.get('children'): access_next_level(path, i) else: print(f"当前小节ID:{item.get('id')},小节名称:{item.get('sectionName')}") record_id = 1 wb = load_workbook(filename='sample.xlsx') ws = wb.active rows = ws.rows get_test_question(item.get('id')) # 判断目录是否存在 if not os.path.exists(path): os.makedirs(path) wb.save(f'{path}/{item.get("sectionName")}.xlsx') def get_product_course_info(id): response = requests.get('https://wx.yiwenjy.cn/yunlian_pc/queryProductCourse', params={ 'id': id }, headers=common_headers).json() data = response.get('data') """ 每个ITEM courseName:"中国建设银行VIP" examId:"43d8625d21614cab9f6a2e323e0cd4db" id:"1686999432228376576" """ return data def query_paper_type_list(id): response = requests.get('https://wx.yiwenjy.cn/yunlian_pc/queryPaperTypeList', params={ 'courseId': id }, headers=common_headers).json() """ "id": "1", "paperTypeName": "章节练习", "icon": null, "version": null, "isSection": null, "hasSection": null """ return response.get('data') def get_li_nian_zhen_ti_list(id, paperTypeId): response = requests.get('https://wx.yiwenjy.cn/yunlian_pc/queryPaperList', params={ 'courseId': id, 'paperTypeId': paperTypeId }, headers=common_headers).json() """ 每个ITEM "id": "1703299201187844096", "paperName": "2022年银行招聘笔试《中国建设银行》试题", "onlineTime": "2023-09-17 00:00:00", "referenNumber": 139, "tryBuy": 1, "hasMake": 3, "mode": null """ return response.get('data') course = [ {'id': 'f753f9934c60427fadfba664229a8487', 'name': '2024年军队文职人员招聘《公共科目》题库'} ] for courseItem in course: # 创建科目的文件夹 if not os.path.exists(courseItem.get('name')): os.makedirs(courseItem.get('name')) product_course_info = get_product_course_info(courseItem.get('id')) for product_course in product_course_info: # 查询当前科目下的试卷类型列表 paper_type_list = query_paper_type_list(product_course.get('id')) for paper_type in paper_type_list: print(f"当前科目:{product_course.get('courseName')},当前试卷类型:{paper_type.get('paperTypeName')}") if paper_type.get('paperTypeName') == '章节练习': get_catalogue(courseItem.get("name"), product_course.get('id')) elif paper_type.get('paperTypeName') in ('历年真题', '考前点题', '模拟试卷', '预测试卷', '考前点题'): li_nian_zhen_ti_list = get_li_nian_zhen_ti_list(product_course.get('id'), paper_type.get('id')) for li_nian_zhen_ti in li_nian_zhen_ti_list: record_id = 1 wb = load_workbook(filename='sample.xlsx') ws = wb.active rows = ws.rows print(f"当前试卷ID:{li_nian_zhen_ti.get('id')},试卷名称:{li_nian_zhen_ti.get('paperName')}") get_exam_question(li_nian_zhen_ti.get('id')) wb.save( f'{courseItem.get("name")}/{courseItem.get("name")}-{li_nian_zhen_ti.get("paperName")}.xlsx') else: print("不支持的试卷类型:%s" % paper_type.get('paperTypeName')) exit()
-
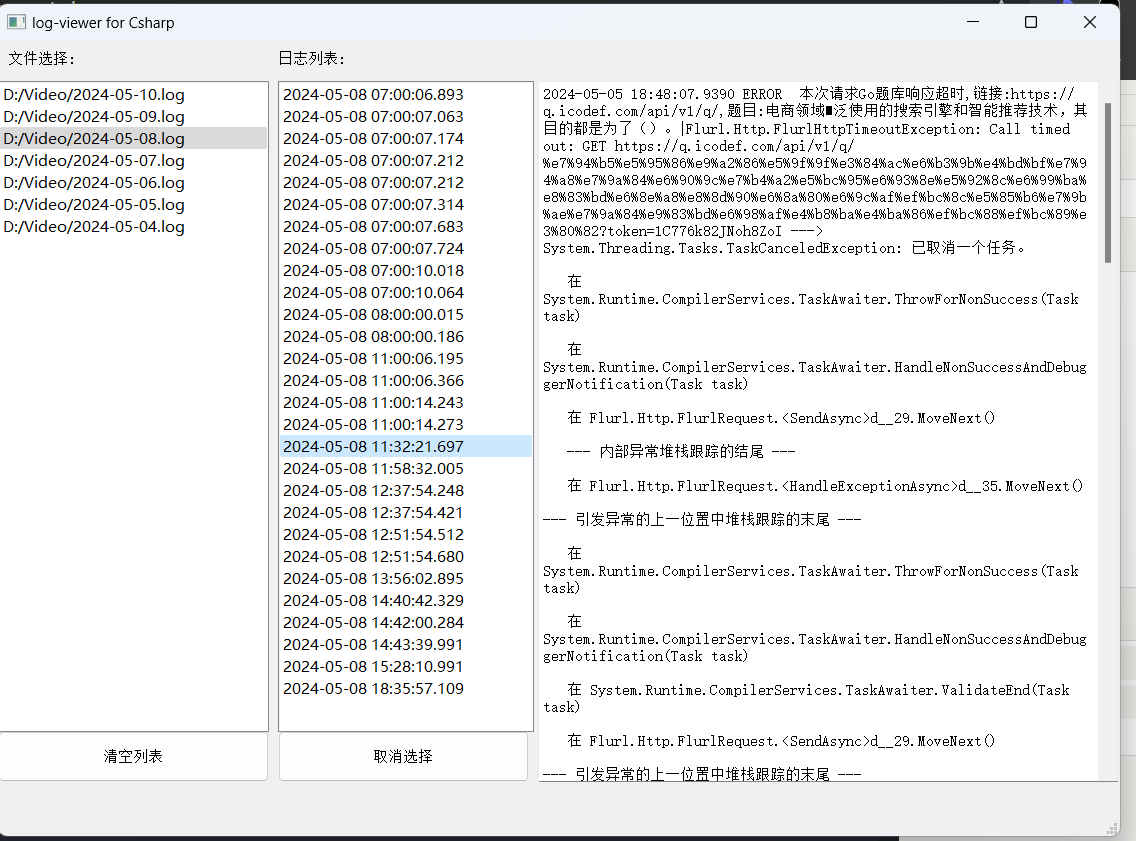
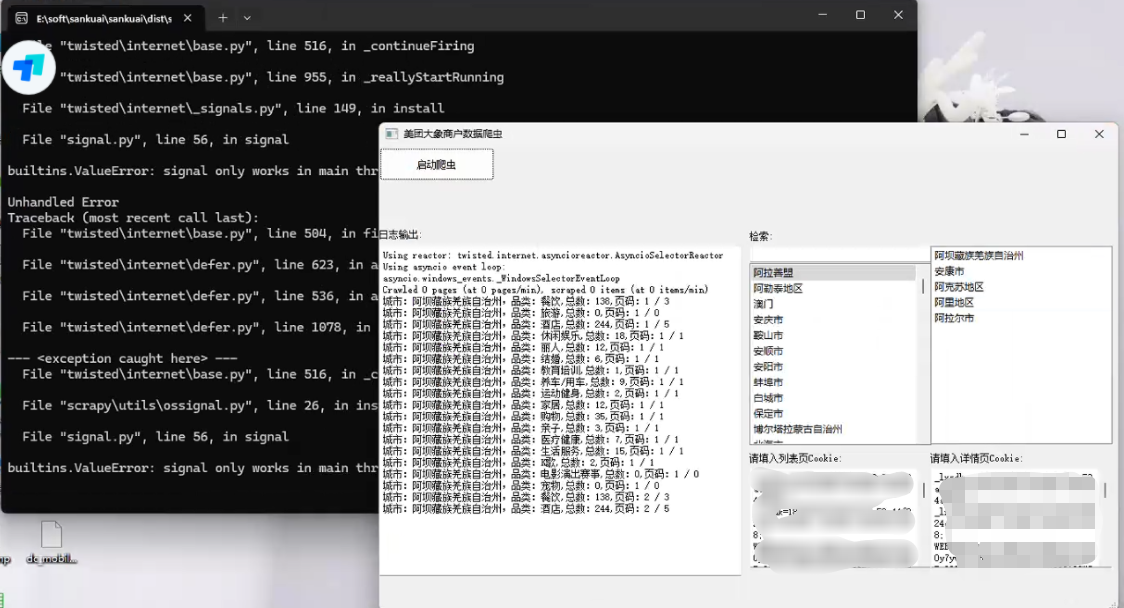
美团旗下大象商户数据爬虫2-为爬虫绘制GUI并打包 前言公司最近的业务,继上文:https://lisok.cn/python/552.htmlcmd命令的使用有点麻烦,于是学习了一下PyQt5画了一个GUI实现有几个点需要提一下这里的日志输出是给logging添加了拦截器日志内容分成两部分如图,其中store记录的是自己代码中打印的,scrapy.utils.log是scrapy内部记录的一些日志统一添加一个handler处理 回调显示在界面上。store.pyfrom ui.mainwindow import signal class MyCustomHandler(logging.Handler): def __init__(self, signals): super(MyCustomHandler, self).__init__() self.signals = signals def emit(self, record): log_message = self.format(record) # 发送消息到 PyQt 界面 self.signals.log_signal.emit(log_message) class StoreSpider(scrapy.Spider): name = "store" allowed_domains = ["sale-pb.sankuai.com", 'crm.sankuai.com'] start_urls = ["https://sale-pb.sankuai.com/apigw/api/poi/ownership/poi-not-cooperated"] baseinfo_url = 'https://crm.sankuai.com/poi/sales/report/baseinfo?shopId={}' pageSize = 60 pageNum = 1 startCategoryId = 0 startRequest = True infoHeaders = {"Content-Type": "application/json; charset=UTF-8"} custom_settings = { 'LOG_LEVEL': 'INFO', 'LOG_FILE': 'sankuai-cus.log', } def __init__(self, *args, **kwargs): log_names = ['store', 'scrapy.utils.log', 'scrapy.extensions.logstats'] # 'scrapy.addons', 'scrapy.extensions.telnet', 'scrapy.middleware', # 'scrapy.crawler', 'scrapy.core.engine', for log_name in log_names: logging.getLogger(log_name).addHandler(MyCustomHandler(signal)) super().__init__(*args, **kwargs) # 设置Cookie self.cookies = kwargs.get('cookies', []) self.crawl_cities_ids = kwargs.get('crawl_cities_ids', []) # ....mainwindow.pyfrom PyQt5.QtCore import QThread, pyqtSignal, QObject from .ui_main_window.ui_mainwindow import Ui_MainWindow cities = [] class MySignal(QObject): log_signal = pyqtSignal(str) signal = MySignal() cookies = [] crawl_cities_ids = [] # ...其他的代码都很常规,打个包记录一下{cloud title="美团-大象商户爬虫.zip" type="bd" url="/我的分享/美团-大象商户爬虫.zip" password=""/}引用1.python scrapy框架 日志文件:https://blog.csdn.net/weixin_45459224/article/details/1001425372.[Python自学] PyQT5-子线程更新UI数据、信号槽自动绑定、lambda传参、partial传参、覆盖槽函数:https://www.cnblogs.com/leokale-zz/p/13131953.html3.[ PyQt入门教程 ] PyQt5中多线程模块QThread使用方法:https://www.cnblogs.com/linyfeng/p/12239856.html4.Scrapy Logging:https://docs.scrapy.org/en/latest/topics/logging.html#logging-configuration5.在线程中启动scrapy以及多次启动scrapy报错的解决方案(ERROR:root:signal only works in main thread):https://blog.csdn.net/Pual_wang/article/details/106466017
-
美团旗下大象商户数据爬虫1-Python将Scrapy程序打包成exe 本文开发环境:Python3.9前言最近公司有业务开展到爬美团下 大象的商户信息# 主要是这两个域名 allowed_domains = ["sale-pb.sankuai.com", 'crm.sankuai.com']Pycharm在开发机器上采集占用太高了,于是想打包成exe部署到服务器上跑环境配置包配置:包名版本Scrapy2.11.1pyinstaller6.5.0 步骤一、编写程序入口参考官方文档:https://doc.scrapy.org/en/latest/topics/practices.htmlsankuai/run.pyfrom scrapy.crawler import CrawlerProcess from scrapy.utils.project import get_project_settings # 下面的包是项目中用到的包,根据自己的项目自行添加,也可以根据打包运行的报错信息,逐个添加 import js2xml import os settings = get_project_settings() process = CrawlerProcess(settings) process.crawl('store') # 填入你需要运行的文件名 process.start()二、数据保存本来是想用FEED来保存数据,可以通过控制台来控制保存地址sankuai/run.pysettings = get_project_settings() settings.setdict({ 'FEED_FORMAT': 'csv', 'FEED_URI': os.path.join(os.path.dirname(os.path.abspath(__file__)), 'data.csv') }, priority="project") process = CrawlerProcess(settings)但是测试发现只会创建文件,并不会写入数据,这里没有解决 有后续了再贴替代方案使用pipeline.pysankuai/sankuai/pipeline.pyclass SankuaiPipeline: def __init__(self): # data文件夹不存在则创建 if not os.path.exists('./data'): os.mkdir('./data') def process_item(self, item, spider): with open('./data/' + item.get('cityName') + '.csv', 'a+', encoding='gbk', newline='') as f: writer = csv.writer(f) writer.writerow((item.get('cityName'), item.get('phone'), item.get('phone2'))) return item sankuai/sankuai/settings.py# ... # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { "sankuai.pipelines.SankuaiPipeline": 300, } # ...三、打包打包执行命令:pyinstaller.exe .\run.py打包后的文件会位于sankuai/dist/run/run.exe,通过cmd运行项目中读取的文件需要放到同一个运行目录中,我这里是category.json和city.json还有两个Cookie文件四、运行出现KeyError: 'Spider not found:爬虫名,可以将项目源码和打包程序放在一块,即打包时生成时的目录结构,不要改变,拷贝时连同项目整体拷贝,亲测有效。打包时直接将sankuai目录压缩了,不然会出现其他问题,当然安全性没有保障(源码都泄露出去了)公司自用就无所谓了引用1.python 将Scrapy项目打包成exe及注意事项 :https://www.cnblogs.com/zhengxianfa/p/16767965.html2.【scrapy打包】使用pyinstaller将scrapy项目打包成独立可执行exe,及可能遇到的问题和解决方法:https://blog.csdn.net/qq_51543898/article/details/1368468103.The application can not locate Python39.dll (126)找不到指定的模块。解决方法:https://blog.csdn.net/wushaoqiu2011/article/details/1101824974.用Pyinstaller打包Scrapy项目问题解决!!!:https://pyqt5.blog.csdn.net/article/details/79017358
-
selenium爬虫如何防止被浏览器特征抓取反爬 前言爬网站的时候遇到了cf拦截,根据百度到的尝试添加参数还是无法跳过service = Service('msedgedriver.exe') options = Options() # 开启开发者模式 options.add_experimental_option('excludeSwitches', ['enable-automation']) # 禁用Blink运行时功能 options.add_argument('--disable-blink-features=AutomationControlled') driver = webdriver.Edge(service=service)undetected-chromedriverOptimized Selenium Chromedriver patch which does not trigger anti-bot services like Distill Network / Imperva / DataDome / Botprotect.io Automatically downloads the driver binary and patches it.Tested until current chrome beta versionsWorks also on Brave Browser and many other Chromium based browsers, some tweakingPython 3.6++**我主要使用的Edge,介绍说会自动下载Chrome,并没有体验到,于是自己安装了Chrome浏览器代码跟之前selenium的相差不大,成功解决了问题,再没出现过Cf拦截from pyquery import PyQuery as pq import re import time from undetected_chromedriver import ChromeOptions import undetected_chromedriver as uc options = ChromeOptions() options.add_argument('--headless') options.add_argument('--disable-gpu') driver = uc.Chrome(options=options) driver.get('http://...') html_source = driver.page_source doc = pq(html_source) titles = doc.find('tag')引用1.ultrafunkamsterdam/undetected-chromedriver:https://github.com/ultrafunkamsterdam/undetected-chromedriver2.Chrome Headless Detection (Round II):https://intoli.com/blog/not-possible-to-block-chrome-headless/chrome-headless-test.html3.selenium爬虫如何防止被浏览器特征抓取反爬,undetected_chromedriver他来了。:https://blog.csdn.net/wywinstonwy/article/details/118479162
-
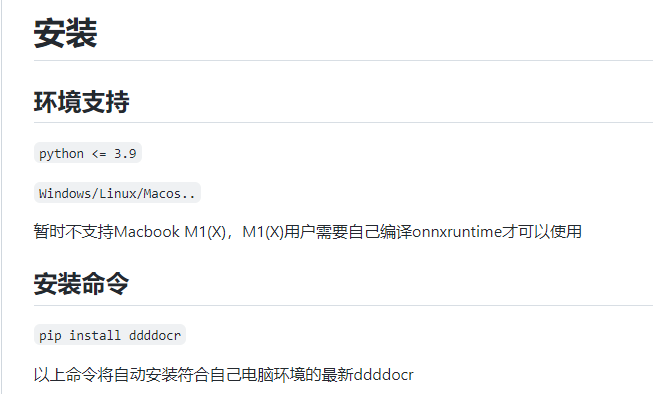
记录一次调用OCR验证码识别库的过程 1.前言最近在写Python项目中用到了其他网站的接口,请求的时候对方接口需要验证码,之前使用的一直是联众打码平台( https://www.jsdati.com/ ),没想到今天访问的时候已经打不开了...{lamp/}谷歌了一下找到了这个库,名字挺有意思哒ddddocr(带带弟弟OCR): https://github.com/sml2h3/ddddocr2.Python版本配置我平常用的是普通的Python3.10+,安装不了这个库,找降低Python版本的方法也没找到。于是就卸载了Python换成带有版本管理的Anaconda,官网: https://www.anaconda.com/ 安装的时候不建议也不需要配置环境变量,控制台使用Anaconda自带的就好基础命令:# 1.创建新环境并指定环境的Python版本 conda create --name env_name python=version 例如: conda create --name python36 python=3.6 # 2.激活环境 activate env_name # 3.关闭环境 deactivate env_name # 4.删除环境 conda env remove -n env_name # 5.显示所有环境 conda env list # 6.查看anaconda中已经存在的镜像源 conda config --show channels # 7.添加镜像源(永久添加) conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ # 8.设置搜索时显示通道地址 conda config --set show_channel_urls yespycharm创建Virtualenv,指定刚才创建的conda环境中python.exe解释器。3.安装ddddocrpip install ddddocr4.使用import ddddocr ocr = ddddocr.DdddOcr(old=True,show_ad=False) with open('stuExam.jpg', 'rb') as f: image = f.read() res = ocr.classification(image) print(res)比较清晰的是可以识别出来的,测试了三个验证码,完全识别正确的只有一张,看来是无法投入到当前项目中使用了。5.参考链接文安哲的博客-ddddocr作者: https://wenanzhe.com/阿迪(GIF)点选验证码识别测试页面:http://146.56.204.113:19199/preview
-
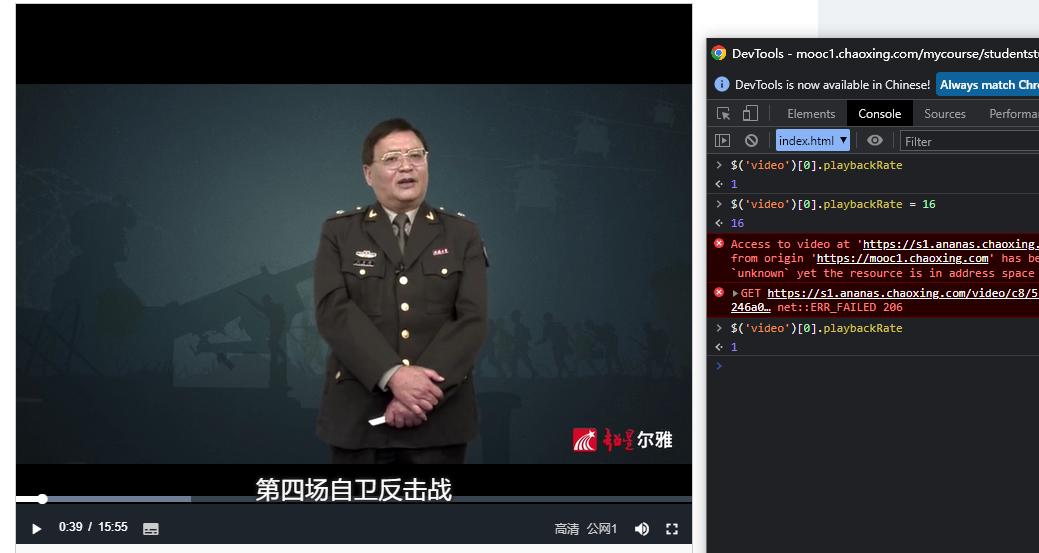
Selenium破解学习通倍速限制 前言学习通的某些课程会有限制播放速度的功能,不仅播放器没有倍速的播放选项,甚至你通过代码修改播放器的速度也会被监听从而被重置播放器的速度。js修改原先尝试过setInterval设置定时器不断的去修改播放器速度,先不说优雅与否,反正是没有用的,每次修改速度,视频都会被暂停,速度也被重置。后面去油猴找了一个插件参考,扒下来了这段破解倍速的代码:{tabs}{tabs-pane label="代码"}(function () { 'use strict'; console.log(window.location.href) function hack() { if (typeof videojs !== "undefined" && typeof Ext !== "undefined") { Ext.define("ans.VideoJs", { override: "ans.VideoJs", constructor: function (b) { b = b || {}; const e = this; e.addEvents(["seekstart"]); e.mixins.observable.constructor.call(e, b); const c = videojs( b.videojs, e.params2VideoOpt(b.params), function () { } ); Ext.fly(b.videojs).on("contextmenu", function (f) { f.preventDefault(); }); Ext.fly(b.videojs).on("keydown", function (f) { if ( f.keyCode === 32 || f.keyCode === 37 || f.keyCode === 39 || f.keyCode === 107 ) { f.preventDefault(); } }); if (c.videoJsResolutionSwitcher) { c.on("resolutionchange", function () { const g = c.currentResolution(); const f = g.sources ? g.sources[0].res : false; Ext.setCookie("resolution", f); }); } }, }); } } if (window.location.href.indexOf('/ananas/modules/video') > -1) { try { hack(); window.document.addEventListener("readystatechange", hack); window.addEventListener("load", hack); } catch (e) { console.error(e.message); } } })();{/tabs-pane}{tabs-pane label="解释"}hack(); window.document.addEventListener("readystatechange", hack); window.addEventListener("load", hack);关键代码是上面这三行,更关键的是执行时机视频播放区域是位于页面的iframe中,/ananas/modules/video就是这个iframe的链接的一部分执行时间:iframe加载时执行,且先于该页面的其他js脚本,一旦页面加载完毕,再去执行代码就没有作用了。{/tabs-pane}{/tabs}破解完之后,再去执行$('video')[0].playbackRate = 16,就发现不会被重置倍速了。应用在Selenium效果:原理就是注入上一节提到的Js# chrome.execute_cdp_cmd会在所有页面加载前进行执行,先于页面自带的Js # 这段压缩过的Js里有判断Url是否为视频页面的逻辑 chrome.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', { 'source': 'function hack(){if(typeof videojs!=="undefined"&&typeof Ext!=="undefined"){Ext.define("ans.VideoJs",{override:"ans.VideoJs",constructor:function(b){b=b||{};const e=this;e.addEvents(["seekstart"]);e.mixins.observable.constructor.call(e,b);const c=videojs(b.videojs,e.params2VideoOpt(b.params),function(){});Ext.fly(b.videojs).on("contextmenu",function(f){f.preventDefault()});Ext.fly(b.videojs).on("keydown",function(f){if(f.keyCode===32||f.keyCode===37||f.keyCode===39||f.keyCode===107){f.preventDefault()}});if(c.videoJsResolutionSwitcher){c.on("resolutionchange",function(){const g=c.currentResolution();const f=g.sources?g.sources[0].res:false;Ext.setCookie("resolution",f)})}},})}}if(window.location.href.indexOf("/ananas/modules/video")>-1){try{hack();window.document.addEventListener("readystatechange",hack);window.addEventListener("load",hack)}catch(e){console.error(e.message)}};'})注意:chrome.execute_script("xxx")的执行是在页面的Js都加载完毕时才会执行,所以使用这个来执行脚本 此处并不适用。参考1.Selenium: How to Inject/execute a Javascript in to a Page before loading/executing any other scripts of the page? : https://stackoverflow.com/questions/31354352/selenium-how-to-inject-execute-a-javascript-in-to-a-page-before-loading-executi 2.OCS网课助手: https://github.com/ocsjs/ocsjs